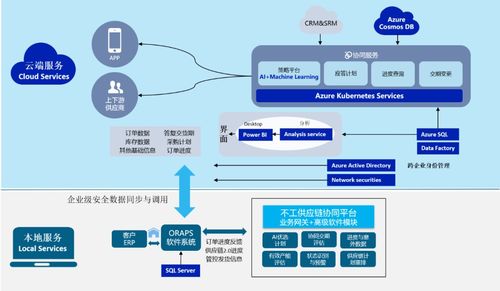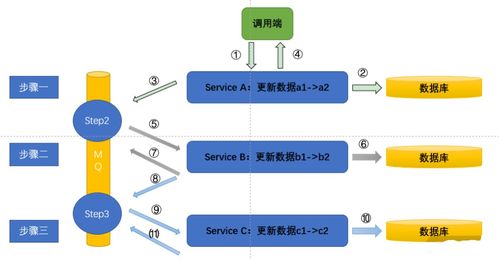
在现代分布式软件架构中,数据处理服务作为上游服务,常常需要与多个下游服务进行交互。当下游服务因故障、网络异常或处理超时等原因失败时,如何确保上游数据处理服务的稳定运行和数据一致性,成为架构设计中的关键挑战。本文探讨了在这一场景下,上游服务实现“独善其身”的核心策略与实践方案。
一、问题背景与核心挑战
数据处理服务作为上游,通常负责接收、清洗、转换或聚合数据,并将结果传递给下游服务(如存储服务、分析服务、通知服务等)。下游服务的失败可能导致数据丢失、重复处理、状态不一致或上游服务阻塞,进而引发连锁反应,影响整个系统的可用性与可靠性。核心挑战在于:如何在保证数据处理逻辑正确的前提下,使上游服务具备容错能力,避免被下游故障拖垮。
二、上游服务“独善其身”的关键策略
1. 异步化与解耦设计
采用消息队列(如Kafka、RabbitMQ)作为缓冲层,将上游服务与下游服务解耦。数据处理服务完成处理后,将结果发布到消息队列,而非直接调用下游接口。下游服务作为消费者从队列中拉取数据,自行处理。即使下游暂时不可用,数据仍会安全存储在队列中,上游服务可继续处理新任务,实现非阻塞运行。
2. 重试机制与退避策略
对于必须同步调用的场景,上游服务应实现智能重试机制。例如,当调用下游失败时,根据错误类型(如网络超时、服务器错误)进行有限次数的重试,并结合指数退避策略(逐步增加重试间隔),避免对下游造成雪崩压力。设置超时时间,防止长时间等待导致上游线程阻塞。
3. 断路器模式(Circuit Breaker)
引入断路器(如Hystrix、Resilience4j)监控下游调用状态。当失败次数超过阈值时,断路器“跳闸”,后续调用直接失败或返回降级结果,不再请求下游。定期允许少量测试请求通过,以检测下游是否恢复,实现自动熔断与恢复。这有效隔离了下游故障,保护上游资源。
4. 本地事务与补偿机制
在涉及数据一致性的场景中,上游服务可采用本地事务确保自身数据状态正确。例如,先将处理结果保存在本地数据库,标记为“待同步”状态,再异步尝试同步到下游。若下游失败,可通过定时任务或事件驱动进行补偿重试,直至成功。结合幂等性设计(如唯一ID),避免重复执行导致数据错误。
5. 监控与告警
建立完善的监控体系,跟踪下游调用成功率、延迟、错误率等指标,并设置告警阈值。当下游服务异常时,上游团队可及时介入,或自动触发降级策略(如切换备用下游、缓存临时数据)。这提升了系统的可观测性与主动应对能力。
三、实践案例:订单处理服务的数据一致性保障
以电商场景为例,订单处理服务(上游)在完成支付后,需通知库存服务(下游)扣减库存。若库存服务失败,订单服务可采取以下步骤:
- 将订单状态更新为“已支付,库存处理中”,并记录日志。
- 通过消息队列发送扣减库存事件,确保事件不丢失。
- 监听库存服务的响应:若成功,更新订单为“已完成”;若失败,触发重试机制,并告警人工干预。
- 在重试期间,订单服务可继续处理其他订单,不受阻塞。
四、
下游服务失败时,上游数据处理服务要“独善其身”,关键在于通过异步化、重试、断路器、事务补偿等架构模式,实现服务间的弹性解耦与故障隔离。这不仅提升了单个服务的健壮性,也保障了整体系统的数据一致性与高可用性。在实际设计中,需根据业务场景权衡一致性要求(如强一致或最终一致),选择合适的技术组合,构建 resilient 的分布式系统。